Metoda ta zaproponowana przez Allana Albrechta (IBM) w 1979 bazowała na projektach ekranów oraz architekturze systemu. Była to próba przezwyciężenia problemów związanych z użyciem liczby linii kodu (która nie jest znana na etapie definicji wymagań a była podstawą do estymacji) jako miary wielkości oprogramowania i jednocześnie próba opracowania metody przewidzenia wysiłku związanego z produkcją oprogramowania. W metodzie tej występowało pięć głównych klas atrybutów produktywności, które charakteryzowały system:
- zewnętrzne wejścia (ang. External Inputs)
- zewnętrzne wyjścia (ang. External Outputs)
- zewnętrzne zapytania (ang. External Inquires)
- pliki wewnętrzne (ang. Internal Logical Files)
- pliki zewnętrzne (ang. External Interface Files)
Dla każdej kategorii zdefiniowane były trzy stopnie złożoności:
prosty,
średni i
złożony. Z kolei z każdym stopniem złożoności były związane ustalone wartości wag.
Tabela 1. Poziomy złożoności elementów przetwarzania
|
l.p. (i)
|
Elementy przetwarzania
|
Poziom złożoności elementu (j)
|
|
prosty
|
średni
|
złożony
|
|
1
|
zewnętrzne wejścia
|
3
|
4
|
6
|
|
2
|
zewnętrzne wyjścia
|
4
|
5
|
7
|
|
3
|
pliki wewnętrzne
|
7
|
10
|
15
|
|
4
|
pliki zewnętrzne
|
5
|
7
|
10
|
|
5
|
zewnętrzne zapytania
|
3
|
4
|
6
|
W metodzie punktów funkcyjnych należało zidentyfikować wszystkie wskazane komponenty systemu i
zakwalifikować je do jednej z klas złożoności. Następnie wyliczano globalną wartość
nieskorygowanych punktów funkcyjnych wg formuły:
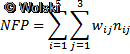
gdzie:
- NFP – nieskorygowane punkty funkcyjne,
- w – wartość współczynnika wagi,
- n – liczba elementów w projekcie,
- i – numer elementu przetwarzania,
- j – numer poziomu złożoności.
Następnie przeprowadzało się
korekcję wyliczonych wartości punktów funkcyjnych w związku z warunkami realizacji systemu. Określało się uwarunkowania realizacyjne konkretnego systemu, podając wpływ 14 czynników. Każdy z czynników oceniany był w skali od 0 do 5, gdzie 0 oznaczał brak wpływu, a 5 bardzo duży wpływ. Wyróżniano współczynniki korygujące poprzez próbę odpowiedzi na następujące pytania:
- Czy jest wymagane przesyłanie danych?
- Czy są funkcje przetwarzania rozproszonego?
- Czy wydajność ma kluczowe znaczenie?
- Czy system ma działać w mocno obciążonym środowisku operacyjnym?
- Czy system wymaga wprowadzania danych on-line?
- Czy wewnętrzne przetwarzanie jest złożone?
- Czy kod ma być re-używalny?
- Czy wejścia, wyjścia, pliki i zapytania są złożone?
- Czy wprowadzanie danych on-line wymaga transakcji obejmujących wiele ekranów lub operacji?
- Czy pliki główne są aktualizowane on-line?
- Czy system ma mieć automatyczne konwersje i instalacje?
- Czy system wymaga mechanizmu kopii zapasowych i odtwarzania?
- Czy system jest projektowany dla wielu instalacji w różnych organizacjach?
- Czy aplikacja jest projektowana, aby wspomagać zmiany i być łatwą w użyciu przez użytkownika?
Następnie należało wyliczyć kompleksowy współczynnik korygujący na podstawie poniższej formuły:
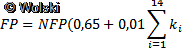
gdzie:
- FP – kompleksowa wartość skorygowanych punktów funkcyjnych,
- NFP – nieskorygowana wartość punktów funkcyjnych,
- k – wartość współczynnika korygującego.
Wielkości 0,65 i 0,01 to
stałe współczynniki, ustalone na podstawie doświadczeń i badań statystycznych wykonywanych systemów.
Ostatnim krokiem było wyznaczenie
pracochłonności, które polegało na odczytaniu wartości pracochłonności w zależności od wyliczonej wartości skorygowanego punktu funkcyjnego FP.
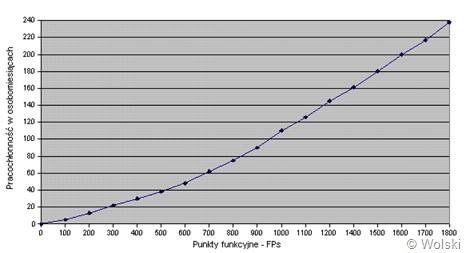 Punkty funkcyjne a pracochłonność
Punkty funkcyjne a pracochłonność